请注意,本文编写于 139 天前,最后修改于 139 天前,其中某些信息可能已经过时。
目录
窗口函数和聚合函数的区别在于,窗口函数为每一行记录都返回一个结果,而聚合函数为每个分组返回一个结果。
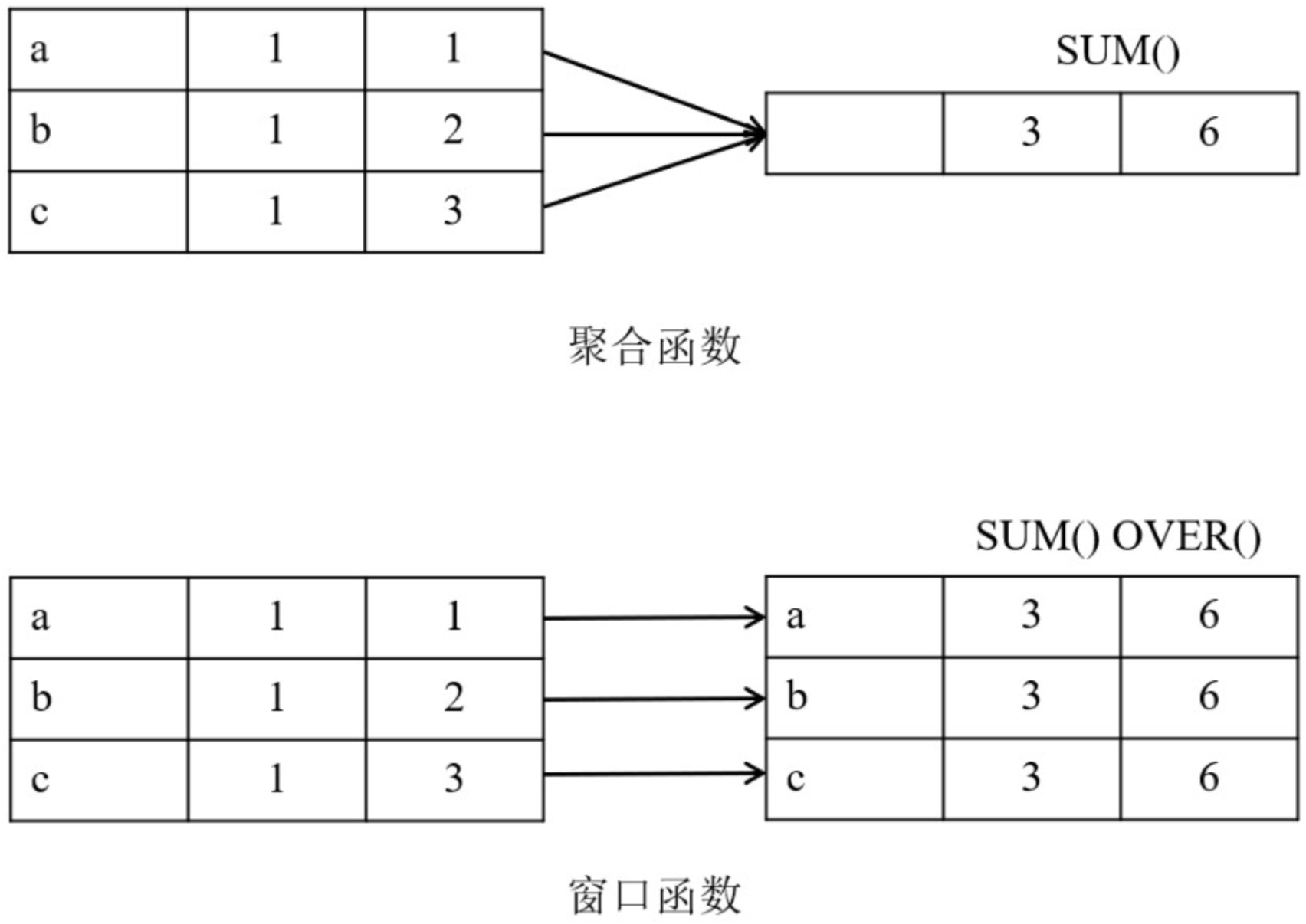
定义
在某些数据库中,窗口函数也被称为在线分析处理(OLAP)函数,或者分析函数(Analytic Function)。
sqlwin_func_name ([expression]) OVER (
PARTITION BY ... -- 类似 GROUP BY
ORDER BY ...
frame_clause -- 窗口大小
)
frame_clause:
{ ROWS | RANGE } frame_start
{ ROWS | RANGE } BETWEEN frame_start AND frame_end
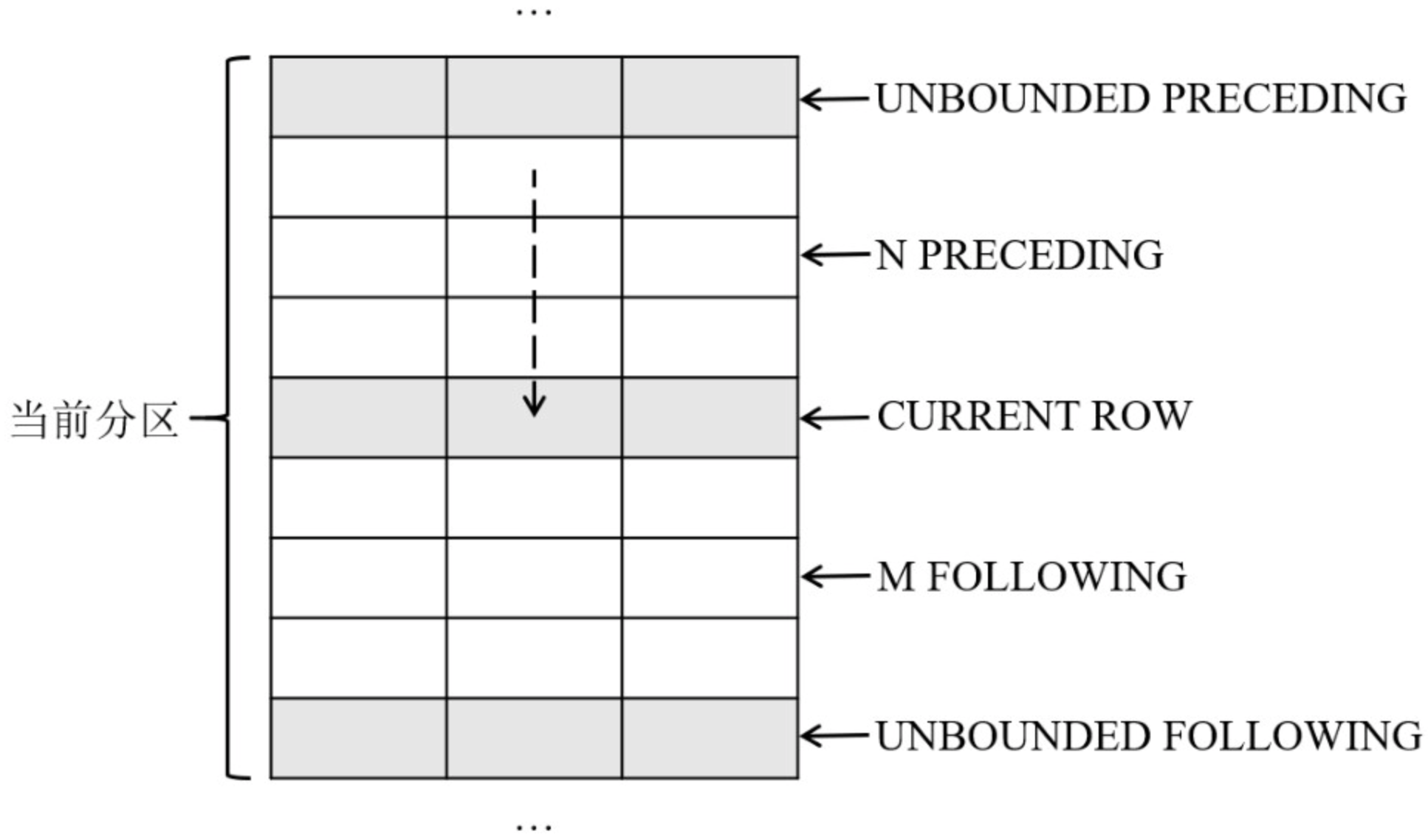
窗口函数 OVER 子句中的 frame_clause 选项用于指定一个移动的分析窗口,窗口总是位于分区的范围之内,是分区的一个子集。
- ROWS 表示以数据行为单位计算窗口的偏移量。
- RANGE 表示以数值(例如10天、5km等)为单位计算窗口的偏移量。
- frame_start 选项用于定义窗口的起始位置
- UNBOUNDED PRECEDING 表示窗口从分区的第一行开始。
- N PRECEDING 表示窗口从当前行之前的第 N 行开始。
- CURRENT ROW 表示窗口从当前行开始。
- frame_end 选项用于定义窗口的结束位置
- CURRENT ROW 表示窗口到当前行结束。
- M FOLLOWING 表示窗口到当前行之后的第 M 行结束。
- UNBOUNDED FOLLOWING 表示窗口到分区的最后一行结束。
理解“当前行”吗?在文章开头说过,窗口函数为每一行记录生成一个结果,“当前行”就表示窗口函数在为哪一行生成结果。
窗口大小选项举例
sqlROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
上面的语句用下图表示
简单使用例子
sql-- 不同部门分别统计员工的月薪合计
SELECT emp_name "员工姓名", salary "月薪", dept_id "部门编号",
SUM(salary) OVER (
PARTITION BY dept_id
) AS "部门合计"
FROM employee;
-- 员工在部门内的月薪排名
SELECT emp_name "姓名", salary "月薪", dept_id "部门编号",
RANK() OVER ( -- 窗口内的数据排序后,RANK 返回从1-n的整数
PARTITION BY dept_id
ORDER BY salary DESC
) AS "部门排名"
FROM employee;
- 对于 oracle、pg 以及 sqlite,窗口函数中的 ORDER BY 也可以使用 NULLS FIRST 或者 NULLS LAST 选项指定空值的排序位置。
聚合窗口函数 Aggregate Window Function
包括 AVG()、SUM()、COUNT()、MAX() 以及 MIN() 等函数。
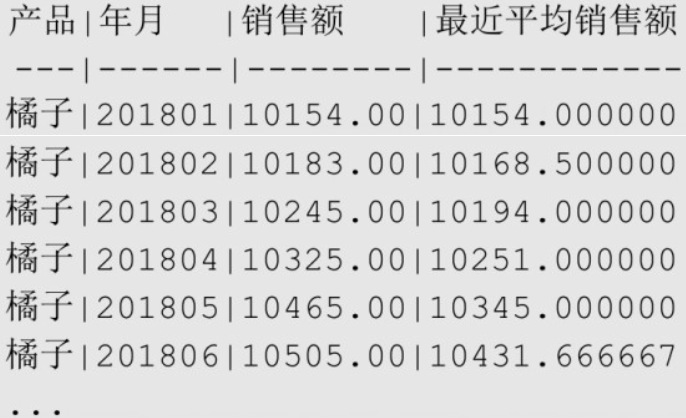
移动平均值
sql-- 获取不同产品每个月销售额、最近3个月平均销售额
SELECT product AS "产品", ym "年月", amount "销售额",
AVG(amount) OVER (
PARTITION BY product
ORDER BY ym
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW -- 从当前行的前2行开始,到当前行结束
) AS "最近平均销售额"
FROM sales_monthly
ORDER BY product, ym;
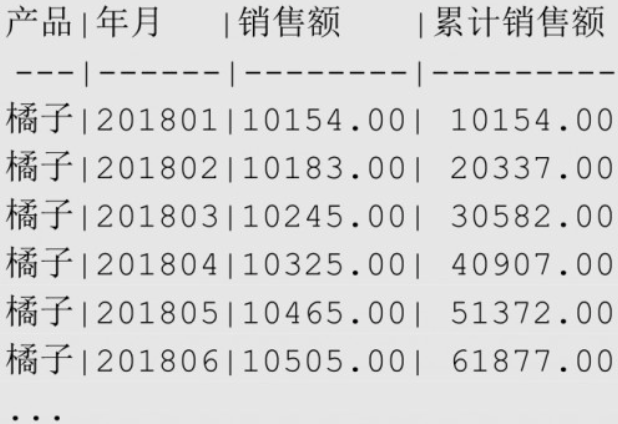
累计求和
sql-- 不同产品截至当前月份的累计销售额
SELECT product AS "产品", ym "年月", amount "销售额",
SUM(amount) OVER (
PARTITION BY product
ORDER BY ym
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW -- 从当前分区第一行开始,到当前行结束
) AS "累计销售额"
FROM sales_monthly
ORDER BY product, ym;
- 对于聚合窗口函数,如果没有指定 ORDER BY 选项,默认的窗口大小就是整个分区。如果指定了 ORDER BY 选项,默认的窗口大小就是分区的第一行到当前行。
sql-- 查找短期之内(5天)累计转账超过100万元的账户
-- oracle mysql pg
SELECT log_ts, from_user, total_amount
FROM (
SELECT log_ts, from_user,
SUM(amount) OVER (
PARTITION BY from_user
ORDER BY log_ts
RANGE INTERVAL '5' DAY PRECEDING -- 根据排序的 log_ts,从前5天开始,到当前结束
) AS total_amount
FROM transfer_log
WHERE TYPE = '转账'
) t
WHERE total_amount >= 1000000;
-- sqlite 不支持 INTERVAL,但是可以将时间转为整数
WITH t1(log_ts, unix, from_user, amount) AS (
SELECT log_ts, CAST(STRFTIME('%s', log_ts) AS INT), from_user, amount
FROM transfer_log
WHERE type = '转账'
)
SELECT log_ts, from_user, total_amount
FROM (
SELECT log_ts, from_user,
SUM(amount) OVER (
PARTITION BY from_user
ORDER BY unix
RANGE 5 * 86400 PRECEDING
) AS total_amount
FROM t1
) t
WHERE total_amount >= 1000000;
- mss 中的 RANGE 窗口大小选项只能指定 UNBOUNDED PRECEDING、UNBOUNDED FOLLOWING 或者 CURRENT ROW。
排名窗口函数 Ranking Window Function
包括 ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()、CUME_DIST() 以及 NTILE() 等函数。
- ROW_NUMBER 函数可以为分区中的每行数据分配一个序列号,序列号从1开始。
- RANK 函数返回当前行在分区中的名次。如果存在名次相同的数据,后续的排名将会产生跳跃。
- DENSE_RANK 函数返回当前行在分区中的名次。即使存在名次相同的数据,后续的排名也是连续值。
- PERCENT_RANK 函数以百分比的形式返回当前行在分区中的名次。如果存在名次相同的数据,后续的排名将会产生跳跃。
- CUME_DIST 函数计算当前行在分区内的累积分布。
- NTILE 函数将分区内的数据分为N等份,并返回当前行所在的分片位置。
- 排名窗口函数不支持动态的窗口大小选项,而是以整个分区作为分析的窗口。
排名函数比较
sqlSELECT d.dept_name AS "部门名称", e.emp_name AS "姓名", e.salary AS "月薪",
ROW_NUMBER() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "row_number",
RANK() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "rank",
DENSE_RANK() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "dense_rank",
PERCENT_RANK() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "percent_rank"
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id);
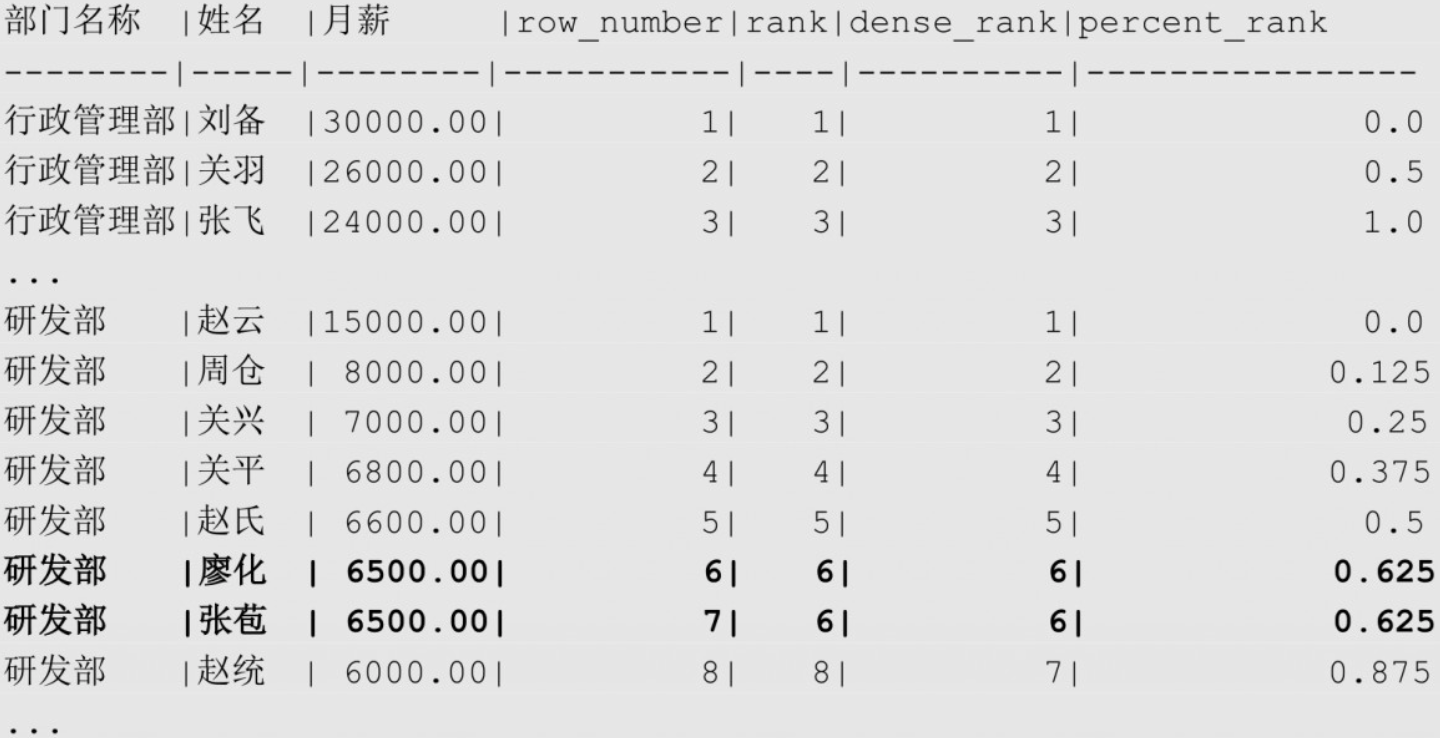
- 可以使用 COUNT() 窗口函数产生和ROW_NUMBER函数相同的结果
更简单的写法
- oracle mss 不支持简写
sql-- mysql pg sqlite
SELECT d.dept_name AS "部门名称", e.emp_name AS "姓名", e.salary AS "月薪",
ROW_NUMBER() OVER w AS "row_number",
RANK() OVER w AS "rank",
DENSE_RANK() OVER w AS "dense_rank",
PERCENT_RANK() OVER w AS "percent_rank"
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
WINDOW w AS (PARTITION BY e.dept_id ORDER BY e.salary DESC);
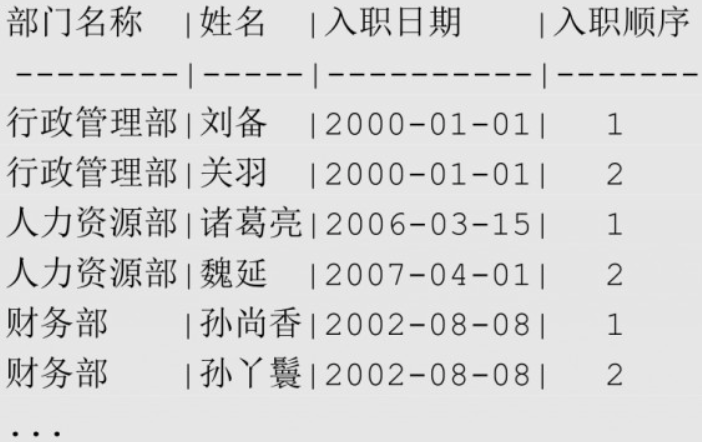
sql-- 查找每个部门中最早入职的2名员工
WITH ranked_emp AS (
SELECT d.dept_name, e.emp_name, e.hire_date,
ROW_NUMBER() OVER (PATRITION BY e.dept_id ORDER BY e.hire_date) AS rn
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
)
SELECT dept_name "部门名称", emp_name "姓名", hire_date "入职日期", rn "入职顺序"
FROM ranked_emp
WHERE rn <= 2;
累计分布
CUME_DIST 返回排名在当前行之前(包含当前行)所有数据所占的比率。
sqlSELECT emp_name AS "姓名", salary AS "月薪",
CUME_DIST() OVER (ORDER BY salary) AS "累计占比"
FROM employee;
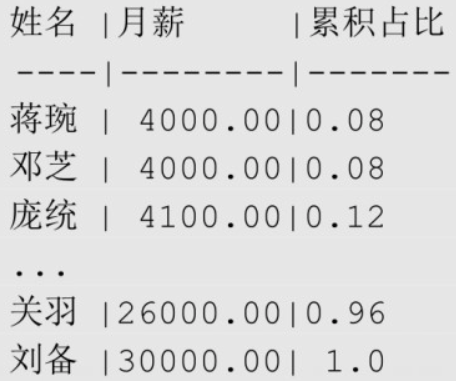
- 结果显示8%的员工月薪小于或等于4000元
sql-- 将员工按照入职先后顺序分为5组,并计算每个员工所在的分组
SELECT emp_name AS "姓名", hire_date AS "入职日期",
NTILE(5) OVER (ORDER BY hire_date) AS "分组位置"
FROM employee;
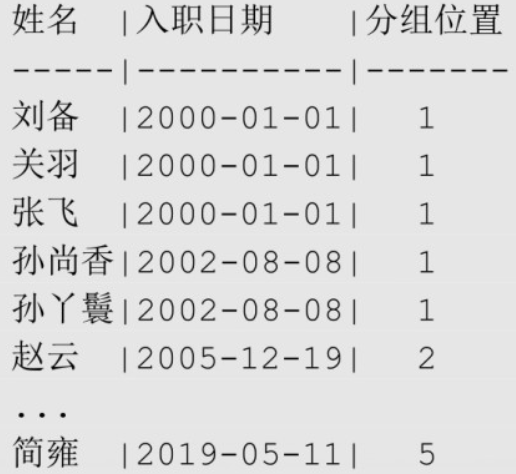
取值窗口函数 Value Window Function
用于返回指定位置上的数据行,包括 FIRST_VALUE()、LAST_VALUE()、LAG()、LEAD()、NTH_VALUE() 等函数。
- LAG 函数可以返回窗口内当前行之前的第 N 行数据。
- LEAD 函数可以返回窗口内当前行之后的第 N 行数据。
- FIRST_VALUE 函数可以返回窗口内第一行数据。
- LAST_VALUE 函数可以返回窗口内最后一行数据。
- NTH_VALUE 函数可以返回窗口内第 N 行数据。
- 其中,LAG 函数和 LEAD 函数不支持动态的窗口大小,它们以整个分区作为分析的窗口。
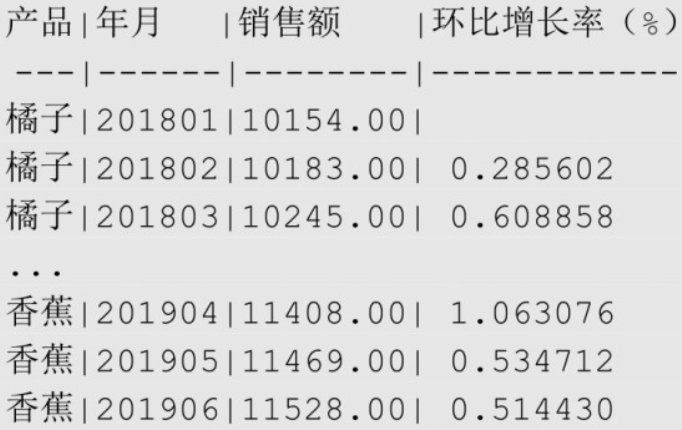
环比
指的是本期数据与上期数据相比的增长,(后一期数据 - 前一期数据) / 前一个数据 * 100%。
sql-- 各种产品每个月的环比增长率
SELECT product AS "产品", ym "年月", amount "销售额",
(
(amount - LAG(amount, 1) /*上一期销售额*/ OVER (PARTITION BY product ORDER BY ym)) / LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym)
) * 100 AS "环比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;
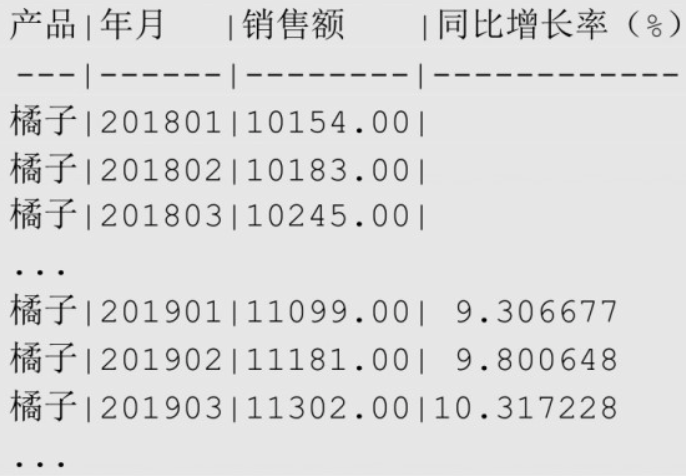
同比
指的是本期数据与上一年度或历史同期相比的增长。
sql-- 各种产品每个月的同比增长率
SELECT product AS "产品", ym "年月", amount "销售额",
(
(amount - LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym)) / LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym)
) * 100 AS "同比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;
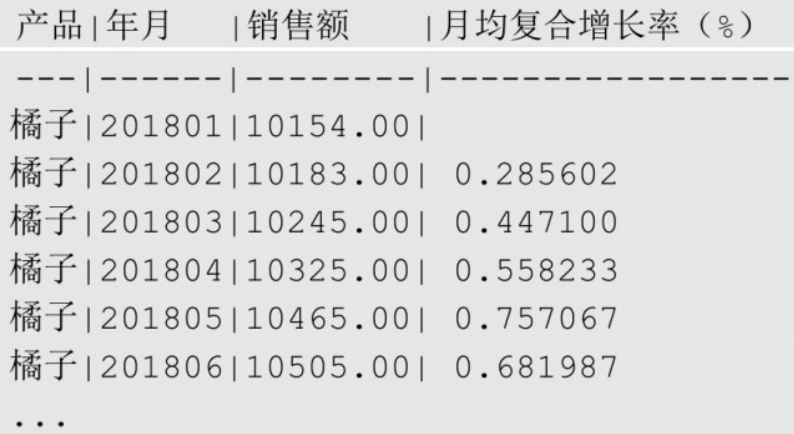
复合增长率
直接上公式
sqlWITH s (product, ym, amount, first_amount, num) AS (
SELECT product, ym, amount,
FIRST_VALUE(amount) OVER (PARTITION BY product ORDER BY ym),
ROW_NUMBER() OVER (PATRITION BY product ORDER BY ym)
FROM sales_monthly
)
SELECT product AS "产品", ym "年月", amount "销售额",
(
POWER(1.0*amount/first_amount, 1.0/NULLIF(num-1,0)) - 1
) * 100 AS "月均复合增长率(%)"
FROM s
ORDER BY product, ym;
sql-- 不同产品最低销售额、最高销售额以及第三高销售额所在的月份
SELECT product AS "产品", ym "年月", amount "销售额",
FIRST_VALUE(ym) OVER (
PARTITION BY product ORDER BY amount DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS "最高销售额月份",
LAST_VALUE(ym) OVER (
PARTITION BY product ORDER BY amount DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS "最低销售额月份",
-- mss 不支持 NTH_VALUE
NTH_VALUE(ym, 3) OVER (
PARTITION BY product ORDER BY amount DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS "第三高月份"
FROM sales_monthly
ORDER BY product, ym;
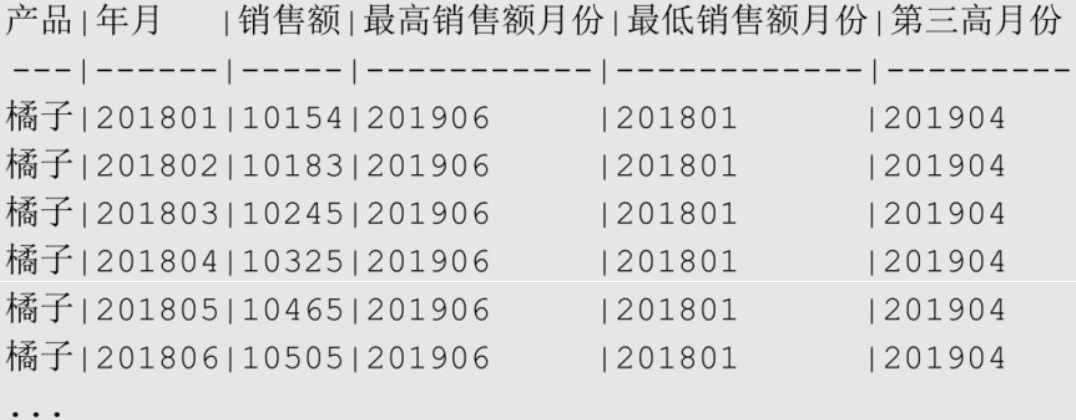
- FIRST_VALUE、LAST_VALUE、NTH_VALUE 的默认窗口都是从分区的第一行到当前行。
本文作者:jdxj
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录