目录
Chat Generative Pre-trained Transformer
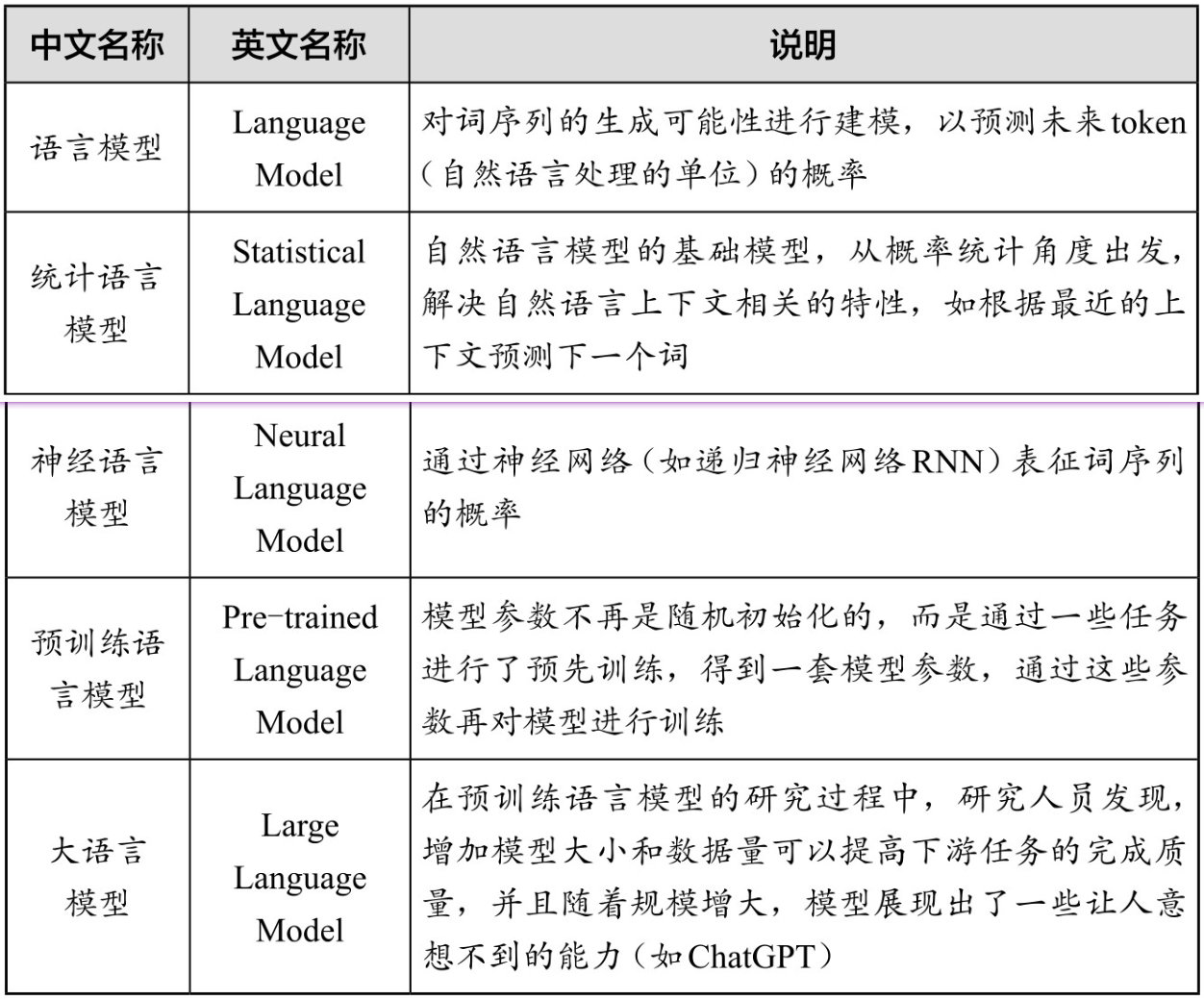
什么是语言模型
语言模型可以理解为一种预测下一个token(自然语言处理的单位,可以简单理解为词)的统计模型。举例来说,如果我们输入“想吃”,语言模型会预测“饭”是接下来很有可能出现的词。
语言模型与说明
什么是GPT
Generative Pre-trained Transformer
Generative(生成式)
GPT是一种生成式人工智能。它通过计算大量数据中的概率分布,最终可以从分布中生成新的数据。
Pre-trained(预训练)
预训练是指在训练特定任务的模型之前,先在大量的未标注的数据上进行训练,以学习一些基础的、通用的特征或模式。然后, GPT可以通过在有标签的数据上进行微调,来适应各种不同的任务。
Transformer
可以直译为改变者/变换器/变形金刚。
Transformer是一种深度学习模型,它使用自注意力机制来处理序列数据。这使得GPT能够有效地处理长文本,并捕捉到文本中的复杂模式。
自注意力机制
自注意力机制(Self-Attention)是Transformer的核心组成部分。这种机制的主要思想是在处理序列的每个元素时,不仅考虑该元素本身,还考虑与其相关的其他元素。
2017年,谷歌发布了关于Transformer的论文;2018年,OpenAI发布了GPT-1;2020年,OpenAI发布了GPT-3。此后,OpenAI在GPT-3的基础上又进行了人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF)和监督精调(Supervised Fine-tuning)。数次迭代后,ChatGPT(GPT-3.5)就这样训练成了,并在2022年11月发布,引起了全世界的轰动。
ChatGPT的能力
自动写作、命题绘画、语言翻译、智能推荐、分析预测等。它能应用在各行各业,如广告、直播、写作、绘图、新闻等。
Emergence(涌现)
涌现通常用于描述由低层次的简单交互产生的高层次的复杂行为的现象。这些高层次的复杂行为不能直接从简单交互中预测出来,但是在特定的条件和规则下,它们可以从这些交互中“涌现”出来。
蚁群就是“涌现”现象的典型示例
每只蚂蚁的行为看似简单——寻找食物,将食物带回蚁巢,避开危险。但是,当我们观察一群蚂蚁时,我们会看到一种非常复杂的行为模式:它们能够建造非常复杂的蚁巢,能够找到最短的路径把食物带回蚁巢,能够协作防御敌人。
大模型能力的涌现是指在小规模模型中不存在,但在大规模模型中存在的能力。以下三种新能力将使ChatGPT大有作为。
- 上下文理解
- 遵循指令
- 推理能力
如果未来能进一步扩大模型规模,融入更多真实世界的知识, ChatGPT等大语言模型的智能水平将会大幅提升,这使得人工智能取得更大进步成为可能。
“GPT们”会抢走我们的工作吗
很可能会。
2023年3月,OpenAI发布了一篇研究论文GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models(GPTsareGPTs:大语言模型对劳动力市场的潜在影响的早期研究),调查ChatGPT等大语言模型可能对劳动力市场产生的影响。这篇论文的研究主要有以下结论。
- 绝大多数职业在某种程度上都受到大语言模型的影响,美国约80%的劳动者至少有10%的工作任务可能受到ChatGPT等大语言模型的影响,其中约19%的员工可能有50%的工作任务会受到影响。
- 这种影响涉及各个工资水平的职业。除去部分特殊情况,从整体来看,工资水平越高的职业,受ChatGPT的冲击程度越大。
ChatGPT的局限
大语言模型的“幻觉”现象
一本正经地胡说八道。
随着科学家们的努力,“幻觉”的现象已经大幅减少了。在OpenAI的内部评估中,GPT-4产生事实回应的可能性比GPT-3.5增加了40%。
措施
- 事实检查:对于重要的信息,特别是那些可能影响决策的信息,我们应该通过其他可信的来源进行确认。
- 多元化信息源:不要完全依赖人工智能模型来获取信息。尽可能地使用多种不同的信息源,包括人类专家和其他可靠的信息源。
- 了解人工智能的限制:GPT-4和其他人工智能模型并不完美,它们可能产生错误的信息,理解这些限制是不被人工智能“牵着鼻子走”的前提条件。
有限的上下文:ChatGPT的“失忆症”
如果在同一个对话中聊得太多,ChatGPT就会忘记最开始的对话内容。
为什么ChatGPT会“忘记”之前的内容?
“上下文”容量的大小限制了可以记住的内容的多少。随着技术的发展,上下文会越来越长。
为什么不相关的话题最好在不同对话(Chat)里聊?
ChatGPT会一次性读入所有内容,即对话中所有的话题都包括在内,那些信息会对回答产生干扰。
我们和ChatGPT聊天时会觉得它越聊越聪明,是因为我们对它进行了“训练”吗?
模型训练是一个专业的过程,其目的是调整和优化模型的参数,即模型的内部结构。此过程由专业的OpenAI研究人员执行,我们的角色主要是ChatGPT的用户,而不是其训练者。
我们每一次在与ChatGPT进行对话时,ChatGPT对我们的需求、问题背景等的了解就越多,所以就看起来更聪明了。
隐私漏洞与安全隐患
在使用ChatGPT的过程中,会存在个人隐私或组织机密信息泄露等问题。同时,大语言模型庞大的规模使其难以解释生成的具体语言输出。因此,如果泄露了隐私信息,也很难追根溯源并修复问题。
大语言模型的偏见
ChatGPT等大语言模型在训练或标注过程中,所吸收知识中的偏见会影响其回答和判断。
ChatGPT的训练和标注过程通常依靠人工参与,而人自身难免会带有某些偏见和主观倾向,这可能会通过设定聊天内容的“真实”或“正确”答案,传递给ChatGPT并影响其判断标准。
本文作者:jdxj
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!